Semantic Textual Similarity Using Transfer Learning and Embeddings
Abstract:
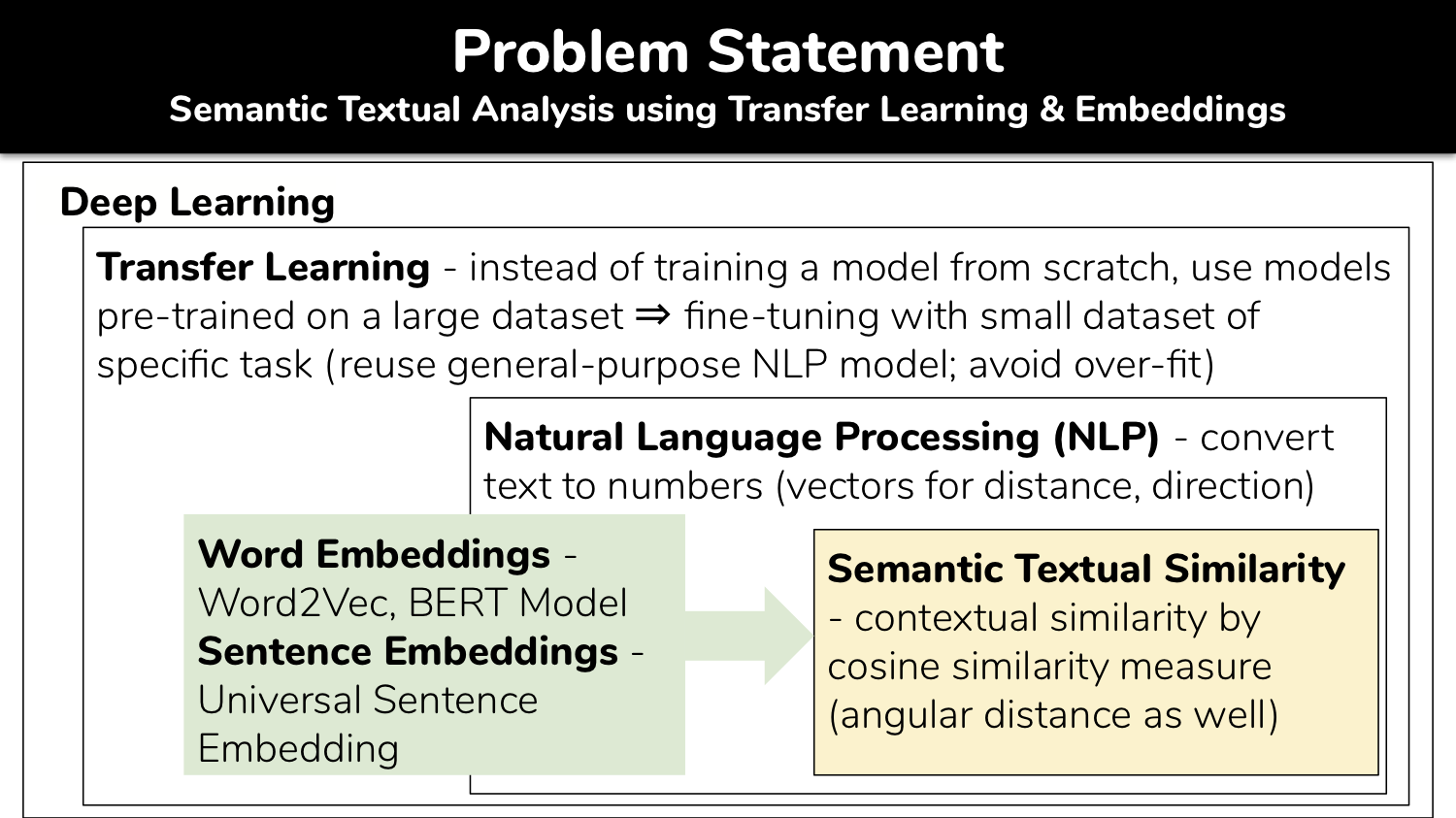
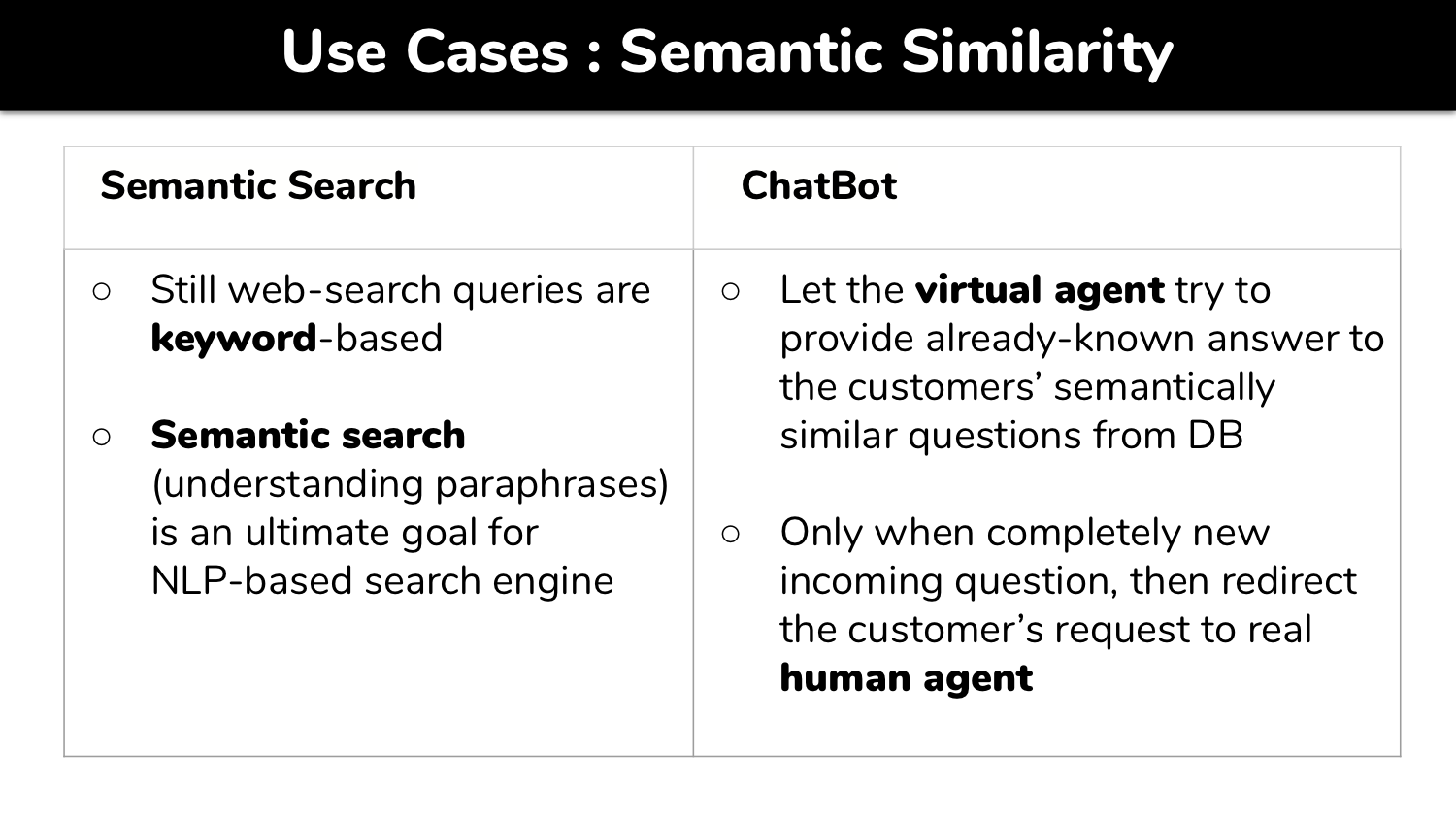
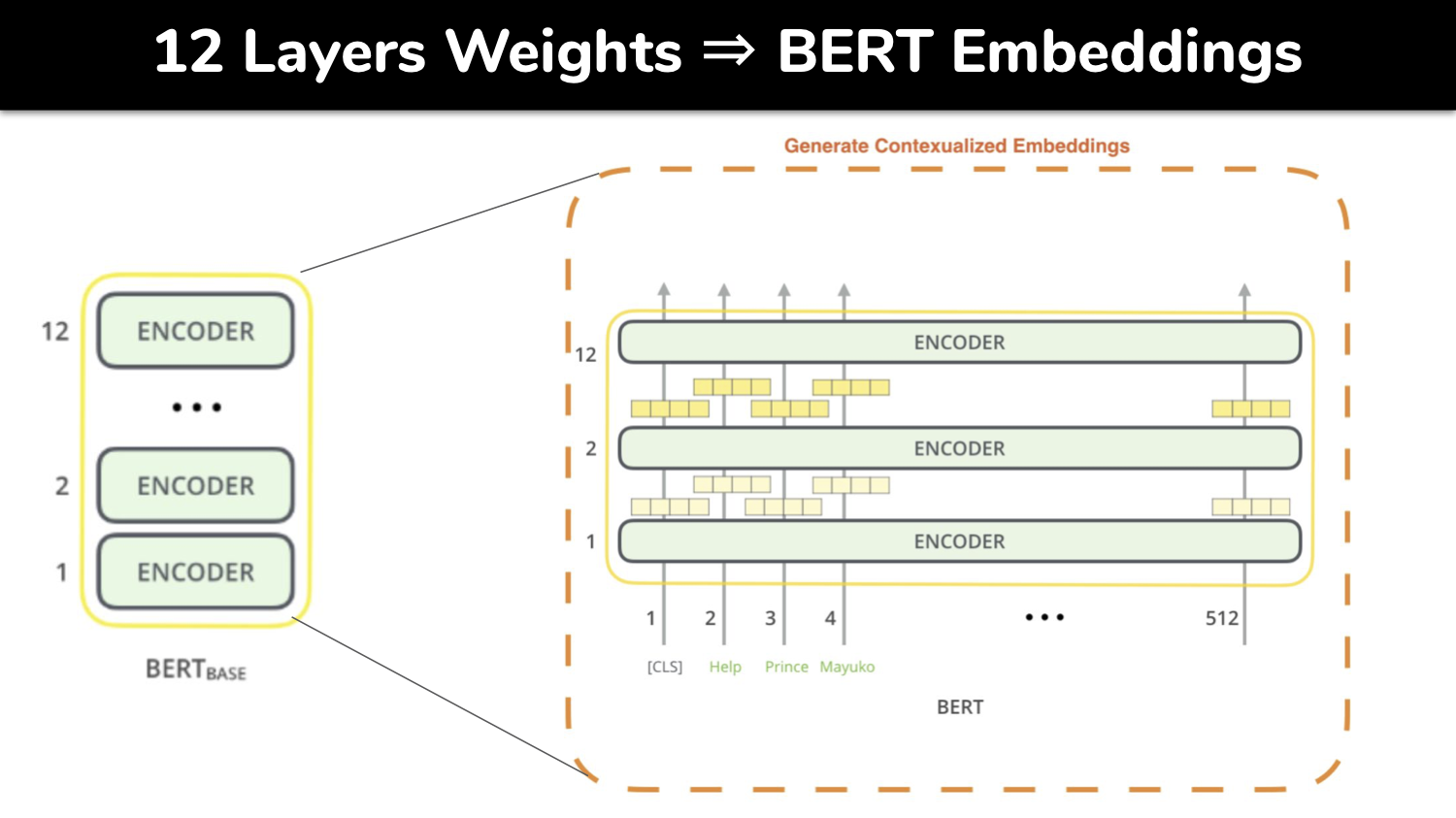
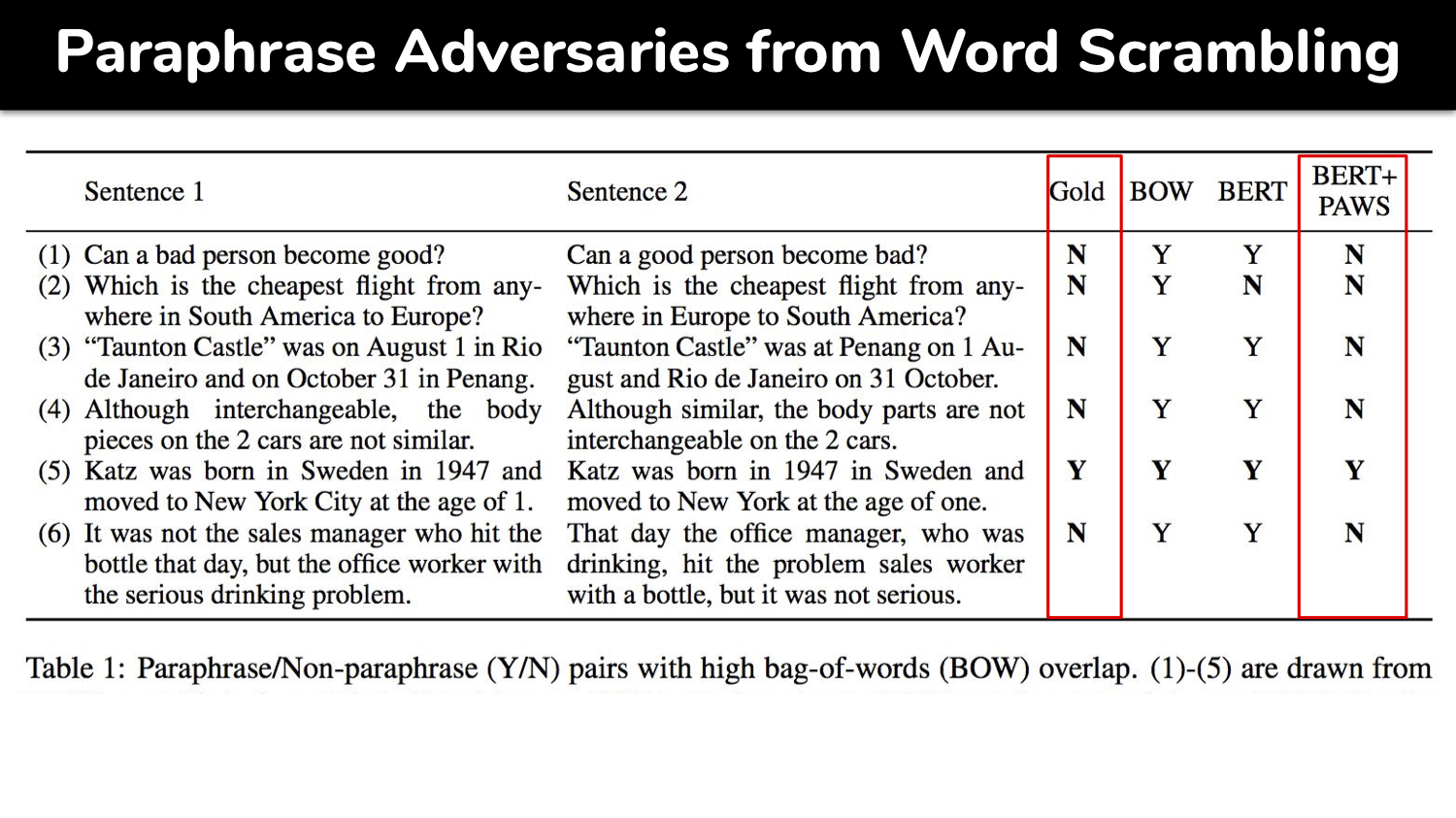
Semantic Textual Similarity (STS) is a one of Natural Language Processing tasks to measure closeness of contextual meaning of given words, sentences or paragraphs as the way of human understands language using a computer model. Owing to the state-of-art, general-purpose, deep learning based NLP model such as BERT, we can build a STS model utilizing Transfer Learning without training a model from scratch. The core theme of this project is to understand word or sentence embeddings, which are features of textual data in numerical representative vectors. We use various embeddings as features to measure semantic metric such as cosine similarity and angular distance similarity. Finally, we build a semantic search engine trained on the Quora Question Set using the best embeddings together with faster and efficient `Approximate k-Nearest Neighbors' (AkNN) in lieu of brute-force cosine similarity metric.
Codes: Colab Notebook
Report: Report